Understanding Text Classification
The Text Classification: View Advanced Information page displays details of the features in your text classes and test text.
To open the Text Classification: View Advanced Information page:
In your experiment, on the Text Classification page, click View advanced info.
| Element | Description |
|---|---|
| Feature |
Click a feature name to see all examples of this feature in the text classes and in the test text. Note: The Examples page displays the examples grouped according to the text class or test text in which they were found. Click a navigation link at the top of the Examples page to see the associated examples. |
| Frequency in Test Text | The total number of appearances of this feature in the test text divided by the total number of all appearances of all features. |
| Frequency |
The frequency of this feature in your text classes, calculated as follows: The upper figure is calculated by taking the total number of appearances of this feature in the text class into which the test text has been classified and dividing it by the total number of all appearances of all features in that text class. The lower figure is calculated by taking the total number of appearances of this feature in the other text class(es) and dividing it by the total number of all appearances of all features in the other text class(es). To see the number of appearances of the feature in the text classes, hover over the numbers. |
| Importance for Classifying this Chapter | The relative importance of this feature in contributing to the classification of the test text, or in the classification of the current chapter, if you have opted to view the test text divided by chapter (see Text Classification Page). |
| Significance in Distinguishing Classes |
The relative significance of this feature in distinguishing between the text classes. |
How does text classification work?
To classify your test text according to the text classes you defined, Tiberias engages in two sets of measurements.
Let’s begin with the measurements that intuitively we know are important to consider in determining classification. Let’s say that you have defined the Book of Jeremiah as one text class and the Book of Ezekiel as the other and that you seek to classify the Book of Lamentations. As you would expect, Tiberias searches for telltale markers of both Jeremiah and Ezekiel within the text of Lamentations and weighs them to reach a conclusion about the classification of Lamentations. Here are the strongest markers of Jeremiah Tiberias finds within the text of Lamentations ch. 5:

Looking at the third row, as an example, you see the data for the feature מפני. Comparing the two columns to the right, you see that this word is of greater significance for distinguishing between the books of Jeremiah and Ezekiel (Significance in Distinguishing Classes column) than it is for classifying Lamentations with the text class of Jeremiah (Importance for Classifying this Chapter column). We see in the middle column, Frequency, that מפני appears 14 times more often in Jeremiah than it does in Ezekiel (0.14%:0.01%). That would appear to be a very strong marker of Jeremiah. However, hovering over those figures, we see that the word appears only 34 times in Jeremiah (against 2 occurrences in Ezekiel), a long book of 52 chapters. Thus, even though the word appears in Jeremiah fourteen times as often as it does in Ezekiel, the frequency of the feature, even in Jeremiah, is somewhat limited, and thus it contributes to the distinction between the classes, but only partially.
The frequency of the feature מפני in ch. 5 of Lamentations is 0.58%, which is more than four times more frequent than it is even in Jeremiah. This high frequency within Lamentations contributes to the classification of the text to the text class of Jeremiah. However, we also can see that this feature figures more prominently in distinguishing the text classes Jeremiah and Ezekiel than it does in classifying Lamentations 5 as Jeremiah. This is because the influence of a feature on the classification of a specific text takes into account three factors:
- the significance of the feature for distinguishing the classes generally
- the frequency of the feature in this specific text as compared to its expected frequency in each class
- the number of other features that play a significant role in the classification of this specific text.
Now we can move on to the measurements Tiberias makes in determining classification that are less intuitive, but no less significant. Scrolling down in the Advanced Information screen, you can see that in addition to measuring the presence of strong markers of Jeremiah and Ezekiel in Lamentations—the well-represented features, Tiberias also measures a second parameter: the under-represented features of the each text-class. In analysis of the text classes, Tiberias learns that there are features that are high in frequency for each class. Any text from that text class would be expected to have it. The under-representation of that feature in the test text can often be the most determining factor in its classification.
Consider what you see when you scroll down in the Advanced information screen here:
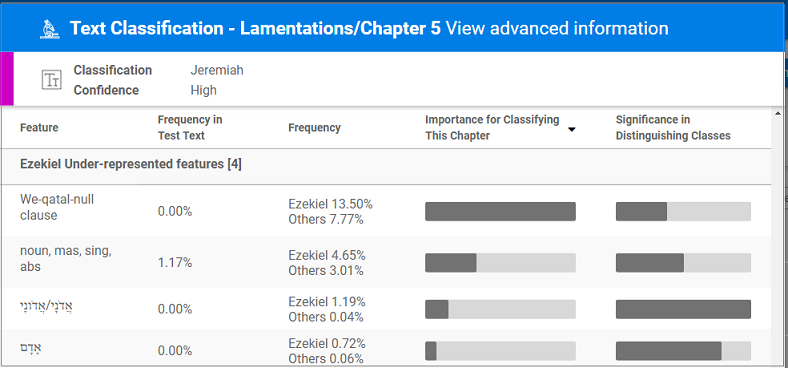
In the fourth line you see the data for the word אדם. The word אדם is twelve times as prevalent in Ezekiel as it is in Jeremiah (0.72%:0.06%). And hovering over those figures, you can see that Jeremiah has 16 occurrences of the word, while Ezekiel has 126. This relatively large quantity is what contributes to the word being a significant factor in distinguishing between the text classes (far right column). It’s total absence from Lamentations (second column, frequency in test text = 0.00%) contributes to the classification that this test text is not typical of the text class of Ezekiel.
The most determining factor in the classification of Lamentations 5 is the data we see in the first line. Clicking on the feature, reveals that these are clauses which open with a qatal form of the verb, preceded by a letter vav. Examples of this: ונלחמו אליך (Jer 1:19); וקראת באזני ירושלים (Jer 2:2). In Ezekiel these appear with a frequency of 13.50%, while in Jeremiah with a frequency of only 7.77%. Although that’s lower than a ratio of 2:1—much lower than what we saw for the word אדם (a ratio of 14:1) - what makes this feature so significant for classification is that it appears 728 times in the Book of Ezekiel, a book of 48 chapters. A typical chapter might be expected to have 15 such clauses. Chapter 5 of Lamentations has none (Frequency in test text = 0.00%). Thus, the absence of this feature contributes more than any other feature—represented or under-represented--to the classification of Lamentations 5 as closer to the text class of Jeremiah than to the text class of Ezekiel.
Classification Confidence
When analyzing your text classes, Tiberias generates an expected accuracy score, indicating the degree of accuracy to be expected when you classify a test text.
Even if you had a high expected accuracy percentage for your text-classes, that does not ensure that Tiberias will be always be able to classify your test text with high confidence. If the test text contains a high number of markers of one of the text classes, and those markers are strongly indicative of that class, then Tiberias will classify your test text with high confidence. However, if your test text contains relatively few markers and these are weak markers of a text-class, Tiberias will classify the test text nonetheless, as closer to that text class. But it will do so with less confidence.